Remove Duplicates
Table of Contents
Removing duplicates is a simple yet powerful technique. It helps eliminate redundancy from data, which can improve the quality and clarity of information. Duplicates can occur in various contexts, such as lists, texts, and databases. By removing these duplicates, you can ensure that your data is accurate and concise.
Why Remove Duplicates?
Duplicates can cause many problems. They clutter the data and make it harder to analyze. For instance, if you are working with a list of customer emails, duplicates can result in sending multiple emails to the same person. This wastes resources and reduces efficiency. Additionally, removing duplicates from text or data ensures that each item is unique, making it easier to process and work with.
Common Areas Where Duplicates Appear
- Text Files: Duplicate words or sentences can make reading harder.
- Databases: Duplicates in databases can cause errors in calculations and data analysis.
- Spreadsheets: Duplicate rows or entries can lead to mistakes in formulas and summaries.
- Emails: Duplicate email addresses or content can lead to unnecessary repetition.
Methods to Remove Duplicates
There are several ways to remove duplicates depending on the type of data you’re working with. Below are a few common methods:
1. Manual Removal
In simple cases, such as text or small lists, you can manually remove duplicates. This method involves reading through the data, identifying repeated entries, and deleting them. While effective for small datasets, this approach can be time-consuming for larger datasets.
2. Using Built-in Tools
For larger datasets, manual removal becomes impractical. Most modern software, like word processors, spreadsheets, and databases, offers built-in tools to remove duplicates.
In Text Editors:
Some text editors allow you to find and remove duplicate words automatically. You can use regular expressions to search for repeated words and delete them.
In Spreadsheets:
Spreadsheets like Microsoft Excel and Google Sheets have features to find and remove duplicates. For example, in Excel, you can select a range of cells and use the “Remove Duplicates” tool from the “Data” tab. This will instantly eliminate any repeating data.
In Databases:
SQL databases provide commands such as DISTINCT to remove duplicates from query results. For example:
SELECT DISTINCT column_name FROM table_name;
This query returns unique entries from the specified column, removing any duplicates.
3. Using Online Tools
Online tools provide a fast and easy way to remove duplicates from text or lists. Websites like “Text Cleaner” or “Duplicate Remover” allow users to paste their data and instantly remove duplicate entries. These tools are ideal for those who don’t want to deal with complex software or programming.
4. Using Programming
For more control over the process, you can use programming languages like Python. Python’s built-in data structures, such as sets, automatically remove duplicates when you convert a list to a set. Here’s a simple example:
data = ['apple', 'banana', 'apple', 'orange']
unique_data = set(data)
print(unique_data)
This will output:
{'banana', 'orange', 'apple'}
Using code to remove duplicates allows you to handle larger datasets more efficiently.
Benefits of Removing Duplicates
Removing duplicates brings several key benefits:
1. Improved Data Quality
Duplicates often lead to errors in analysis or reports. Removing them ensures the data you work with is clean and accurate.
2. Enhanced Readability
When you remove duplicates, the text or data becomes more readable. Repetitive words or rows can be distracting and confusing. Removing them makes the information easier to understand.
3. Increased Efficiency
With duplicates removed, you can process data faster. Whether you’re calculating statistics, generating reports, or analyzing trends, working with clean data makes tasks quicker and more efficient.
4. Reduced Errors
Duplicate entries can lead to errors. For example, sending multiple emails to the same person, counting the same item more than once, or running calculations on repeated values can all cause problems. By removing duplicates, you minimize the chance of errors.
Tools to Help Remove Duplicates
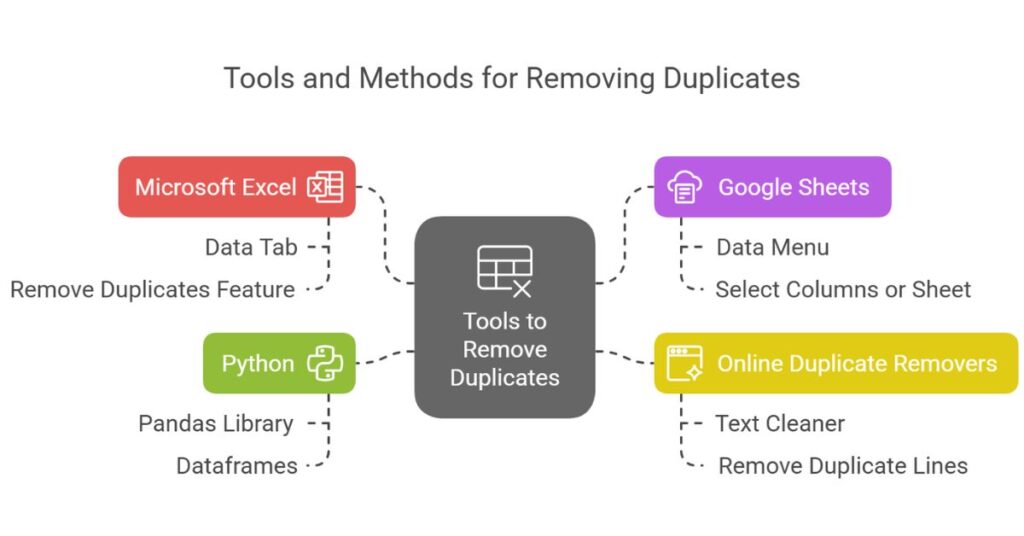
Several tools and software can help with removing duplicates. Here are some commonly used options:
1. Microsoft Excel
Excel has a built-in feature for removing duplicates. You can select your data, click on the “Data” tab, and then choose “Remove Duplicates.” Excel will prompt you to choose which columns to check for duplicates. Once selected, it removes any repeated entries, leaving unique ones.
2. Google Sheets
Google Sheets also has a “Remove Duplicates” feature under the “Data” menu. You can choose to remove duplicates from specific columns or the entire sheet.
3. Online Duplicate Removers
Online tools like “Text Cleaner” and “Remove Duplicate Lines” allow you to paste your text and instantly remove duplicates. These tools are simple and effective for short lists or text blocks.
4. Python (Programming)
If you work with large datasets, using programming languages like Python offers flexibility and efficiency. Python’s pandas library provides a method to remove duplicates from dataframes:
import pandas as pd
df = pd.DataFrame({'col1': [1, 2, 2, 3, 4]})
df.drop_duplicates(inplace=True)
print(df)This will drop duplicate rows and retain unique ones.
Best Practices for Removing Duplicates
Here are some best practices to follow when removing duplicates:
1. Always Backup Your Data
Before removing duplicates, it’s a good idea to back up your original data. This ensures you can recover your data if something goes wrong.
2. Check for False Duplicates
Sometimes, what seems like a duplicate may not be. For instance, you might have similar data in different formats (e.g., “John Doe” and “john doe”). Be sure to check if the duplicates are truly identical.
3. Use Automation for Large Data
For large datasets, manual removal is inefficient. Automate the process using built-in tools, programming, or online tools.
4. Regularly Clean Your Data
Cleaning data regularly ensures that duplicates don’t pile up over time. Make it a habit to review and clean your data periodically.
Conclusion
Removing duplicates is a straightforward process that can improve data quality, efficiency, and readability. Whether you choose manual methods, built-in software tools, online platforms, or programming, removing duplicates can save time and reduce errors. By following the right steps and best practices, you can ensure that your data is clean, accurate, and ready for analysis.